Interactive Timbre Exploration
Ketan Agrawal • Music 220c Final Project
(note: may need to turn volume up)
Timbre Interpolation
Note:
Source instrument:


Target instrument:
0.0
Latent Space Traversal
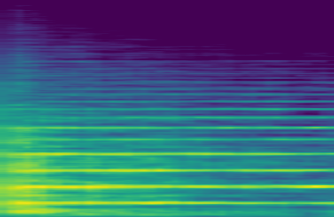
Instrument Piano, varying along zt dimension 1
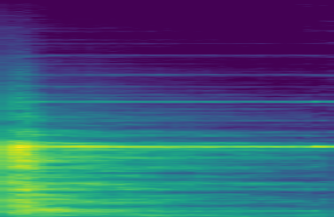
Instrument Saxophone, varying along zt dimension 1

Abstract
The space of human-AI co-creation of content is ripe with possibility; however, many state-of-the-art ML systems today act as “black boxes” that don’t afford end-users any control over their outputs. In the context of creativity, we desire ML systems that are both expressive in their outputs and controllable by an end-user. Specifically in the context of music generation, current models are designed more for listeners than composers. While generative models such as Musenet and GANSynth can create outputs with impressive harmonies, rhythms, and styles, they lack any method for the user to refine those features. If the user doesn’t like the musical output, their only option is to re-generate, producing a completely different composition. Moreover, changing the way these models generate output requires machine learning experience and hours of training time, which is not feasible for composers.
The work presented here represents a step towards AI music generation that is controllable along high-level perceptual dimensions. At the moment, the model used to produce these sounds uses an architecture that separately represents pitch and timbre in its latent space. In the future, I look to extend this to represent other, more high-level perceptual features in the latent space.
Demo
The timbre interpolation samples here were generated using a Gaussian mixture VAE, using the code supplement to the paper Learning Disentangled Representations of Timbre and Pitch for Musical Instrument Sounds Using Gaussian Mixture Variational Autoencoders.In order to generate the interpolation samples, we start with a "source" recording, computing its vector representation, and then adding to some fraction of the vector distance between the source and target distribution means:

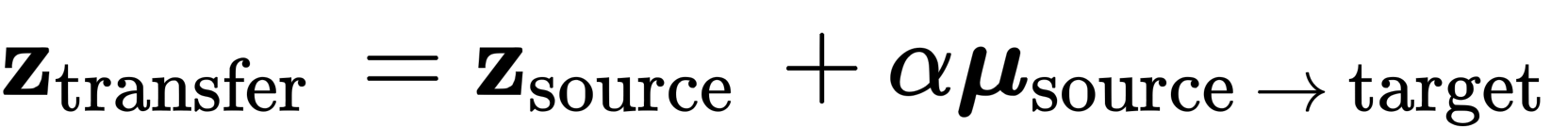
Such interpolations are presented for a small selection of intsruments in the "Timbre Interpolation" demo.
The latent space (z) is composed of 16 separate dimensions. Sometimes, varying the value along one of those dimensions produces perceptually interesting results, as can be seen in the "Latent Space Traversal" demo.
Sidebar: Initially, I focused on training VAEs using modules from the DDSP toolkit; since these neural network architectures have traditional synthesizers embedded into them, the space that they have to learn (synthesizer control parameter space) is much smaller than that of direct waveform generation models, thus allowing models to be vastly smaller. While these models worked to reconstruct the inputs, they didn't quite learn a latent timbre distribution. You can play around with the pretrained model I trained in this Colab notebook.